LLMs in Enhancing ML Workflows on Cloud Platforms
Executive Summary
Automation, orchestration, and efficiency have all been transformed by the incorporation of Large Language Models (LLMs) into Machine Learning (ML) processes on cloud platforms. This case study investigates how LLMs increase cloud-based model training, optimise ML pipelines, guarantee scalable AI installations, and improve workflow execution. To give a thorough insight, important elements including process execution diagrams, solution architecture, pipeline design, and tools used are explained in detail.
1. Introduction
The rise of LLMs has transformed ML workflows, especially on cloud platforms that offer scalable infrastructure. Traditional ML workflows required extensive manual intervention, resource allocation, and optimization. With LLMs, these workflows are now automated, reducing bottlenecks and improving efficiency across data processing, model training, and deployment phases.
Challenges in Traditional ML Workflows:
- High Manual Intervention: Data cleaning, feature engineering, and model tuning often require extensive human effort.
- Scalability Issues: Managing ML training and inference at scale poses infrastructure challenges.
- Time-Consuming Model Deployment: Transitioning from research to production is complex and slow.
- Lack of Workflow Optimization: Poor orchestration leads to inefficiencies in resource utilization.
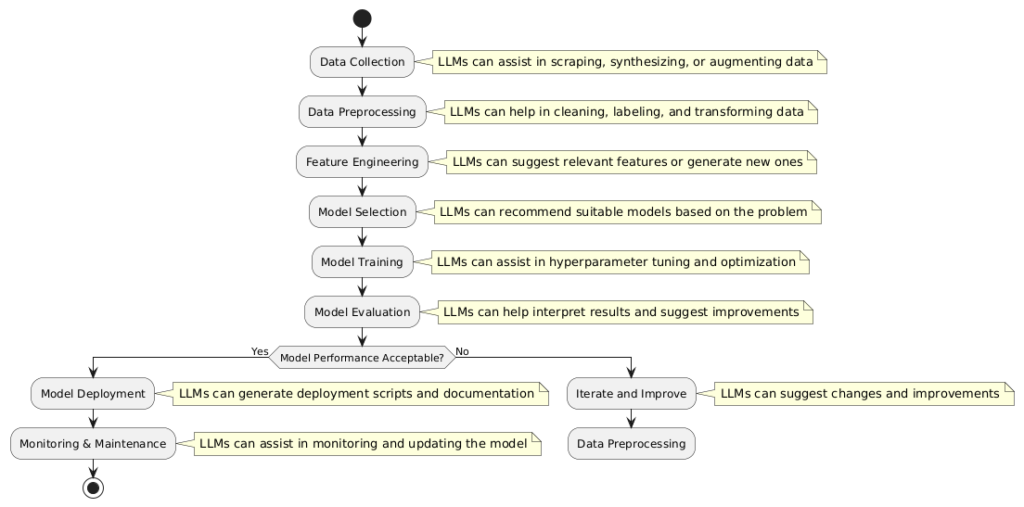
2. LLM-Powered Workflow Execution on Cloud
Workflow Execution Overview:
- Data Ingestion & Preprocessing:
- The first step in any ML workflow is acquiring raw data from various sources, such as databases, cloud storage, APIs, and unstructured sources like text files, images, and logs. LLMs improve data ingestion and preprocessing by automating data extraction, cleansing, transformation, and standardization.
- Feature Engineering & Transformation:
- Feature engineering is one of the most labor-intensive stages of ML workflows. It involves selecting, creating, and transforming variables to enhance model performance. LLMs automate this process, improving efficiency and reducing human bias.
- Model Training & Hyperparameter Optimization:
- Training an ML model requires selecting the right algorithm, tuning hyperparameters, and ensuring proper convergence. LLMs automate hyperparameter tuning and model selection, reducing computational costs while improving accuracy.
- Model Validation & Deployment:
- Before deploying an ML model, it is crucial to validate its performance, conduct error analysis, and ensure robustness. LLMs facilitate model evaluation and automate deployment pipelines.
- Monitoring & Continuous Improvement:
- Post-deployment, models require continuous monitoring to ensure they perform well in real-world scenarios. LLMs assist in model drift detection, retraining, and workflow optimization.
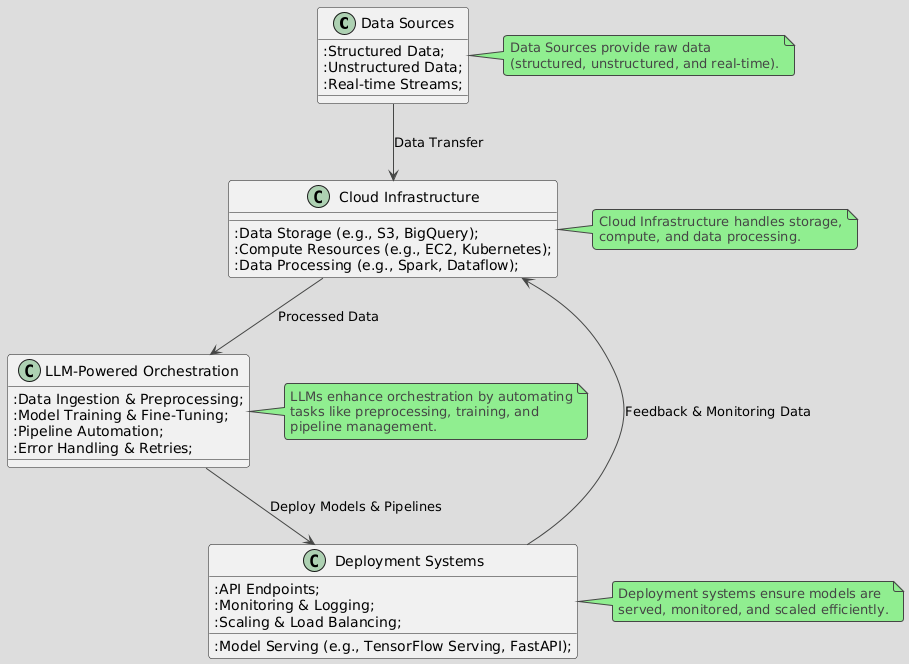
3. Solution Architecture
Key Components of LLM-Based ML Workflows
- Data Ingestion Layer:
- The data ingestion layer is responsible for collecting raw data from multiple sources, including structured and unstructured formats, and storing it in a centralized cloud environment. It acts as the foundation of the ML workflow, ensuring a seamless pipeline for downstream processing.
- Preprocessing & Feature Engineering:
- Once raw data is ingested, it undergoes preprocessing and feature engineering to make it ML-ready. This step involves data cleansing, transformation, and feature selection to improve model performance.
- ML Model Training & Evaluation:
- Training an ML model requires selecting the right algorithm, tuning hyperparameters, and ensuring proper convergence. LLMs automate hyperparameter tuning and model selection, reducing computational costs while improving accuracy.
- Inference & Prediction Pipeline:
- Once the ML model is trained and validated, it is deployed into a cloud environment where it can serve real-time predictions through APIs or containerized microservices.
- Monitoring & Continuous Feedback Loop:
- Post-deployment, ML models require continuous monitoring to ensure they remain accurate and relevant. LLMs automate this process by detecting anomalies, retraining models, and integrating user feedback into iterative updates.
4. ML Pipeline Execution with LLMs
Stages of an LLM-Optimized Pipeline
- Data Collection & Preprocessing:
- The first step in any ML workflow involves collecting and preparing raw data for analysis. This includes cleaning, organizing, and transforming data to ensure high-quality input for model training. LLMs automate this process, making data preprocessing faster and more efficient.
- Feature Selection & Engineering:
- Feature selection and engineering are critical steps in improving model performance. LLMs analyze historical patterns to suggest the most relevant features and automatically create new derived features.
- Model Training & Hyperparameter Optimization:
- Training an ML model requires selecting the right algorithm, tuning hyperparameters, and ensuring proper convergence. LLMs automate hyperparameter tuning and model selection, reducing computational costs while improving accuracy.
- Deployment & Monitoring:
- Once a model is trained and validated, it is deployed into a production environment for real-time inference. LLMs enable automated deployment pipelines and monitoring to ensure performance consistency.
- Continuous Improvement & Feedback Loop:
- ML models require continuous monitoring to ensure they remain accurate and relevant. LLMs automate feedback loops, detect drift, and optimize models based on real-world interactions.
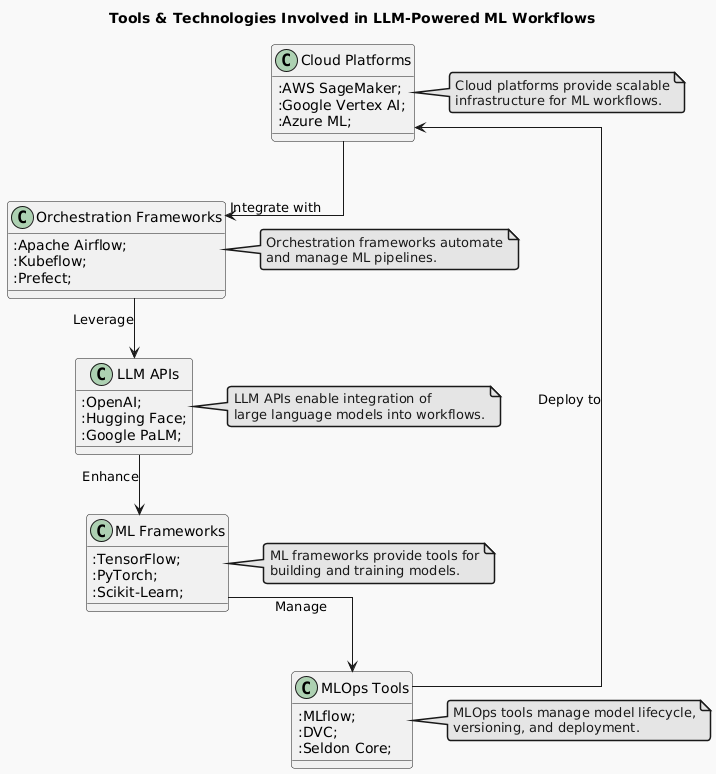
5. Tools & Technologies Involved
Integrating Large Language Models (LLMs) with ML workflows requires the right combination of cloud platforms, orchestration frameworks, APIs, ML frameworks, and MLOps tools.
- Cloud Platforms
- Cloud platforms provide scalability, storage, and compute power to handle ML workloads, including training and deploying LLM-powered workflows.
- AWS SageMaker:
- End-to-end ML development, training, deployment, and monitoring.
- Pre-built algorithms and custom LLM integration.
- Auto-scaling and hyperparameter tuning with built-in optimization.
- Google Vertex AI:
- Supports custom ML models, pre-trained LLMs, and AutoML models.
- Integrates with Google Cloud Storage & BigQuery for large-scale datasets
- Provides serverless inference for efficient deployment.
- Azure ML:
- Scalable ML pipelines, automated hyperparameter tuning, and enterprise-level security.
- Integrates with OpenAI GPT APIs and Azure Cognitive Services for LLM-based applications.
- AWS SageMaker:
- Cloud platforms provide scalability, storage, and compute power to handle ML workloads, including training and deploying LLM-powered workflows.
- Orchestration Frameworks
- Orchestration frameworks automate ML pipelines, ensuring seamless execution of data preprocessing, training, and deployment.
- Apache Airflow
- DAG-based workflow automation for ETL, model training, and deployment.
- Integrates with AWS, Google Cloud, and Azure ML services.
- Kubeflow
- ML pipeline management on Kubernetes.
- Supports end-to-end MLOps automation for LLM training and deployment.
- Prefect
- Python-based orchestration framework with easy cloud integration.
- Automates data ingestion, preprocessing, and model training workflows.
- Apache Airflow
- Orchestration frameworks automate ML pipelines, ensuring seamless execution of data preprocessing, training, and deployment.
- LLM APIs
- Pre-trained LLM APIs allow quick integration of natural language capabilities into ML workflows.
- OpenAI API
- GPT-4, Codex, and fine-tuned models.
- Hugging Face Transformers
- Open-source LLM models for NLP, classification, summarization, etc.
- OpenAI API
- Pre-trained LLM APIs allow quick integration of natural language capabilities into ML workflows.
- ML Frameworks
- Frameworks for training, evaluating, and deploying ML models.
- TensorFlow
- Optimized for deep learning & cloud-based training.
- TensorFlow Serving for fast inference.
- PyTorch
- Dynamic computation graph ideal for LLM training.
- TensorFlow
- Frameworks for training, evaluating, and deploying ML models.
- MLOps Tools
- MLOps tools automate model tracking, deployment, and monitoring.
- MLflow
- Tracks ML experiments & model performance.
- Seldon Core
- Deploys ML models on Kubernetes for scalable inference.
- MLflow
- MLOps tools automate model tracking, deployment, and monitoring.
6. Impact of LLMs on ML Workflows
- Automated Workflow Execution:
- Traditional ML workflows require significant manual intervention, including data preprocessing, feature engineering, hyperparameter tuning, and model deployment. With LLMs, these steps can be automated, reducing time and effort while maintaining accuracy.
- Scalability & Cost Efficiency:
- Cloud-based ML workflows must balance performance with cost-effectiveness. LLMs optimize cloud resource utilization, ensuring that only necessary compute resources are used.
- Enhanced Model Performance:
- LLMs improve ML model training, hyperparameter tuning, and validation, leading to higher accuracy and efficiency.
- Seamless Deployment & Monitoring:
- Traditional ML deployment often faces bottlenecks, including complex CI/CD pipelines, model drift, and operational inefficiencies. LLMs streamline ML model deployment and monitoring, ensuring smooth transitions from research to production.
- Robust Error Handling & Continuous Learning:
- LLMs continuously optimize ML workflows by detecting errors, anomalies, and bias while enabling real-time learning.
7. Conclusion
The integration of LLMs into ML workflows on cloud platforms is transforming the way organizations develop and deploy AI solutions. By automating repetitive tasks, improving data quality, and enhancing model performance, LLMs enable faster, more efficient, and cost-effective ML workflows. However, organizations must address challenges related to data privacy, interpretability, and cost to fully realize the potential of this technology. As LLMs continue to evolve, their role in enhancing ML workflows on cloud platforms will only grow, driving innovation across industries.
Ready to Grow Your Business?
Embark on a transformative journey with us to harness the power of AI and accelerate your success. Let’s innovate and thrive together.